
In the process of investigating Toy PD case, I’ve realised I lack the information about different browser files. This is an attempt to fill that gap.
Many browsers are based on Chromium engine, that’s why they will have similar artifacts: Chrome, Opera, new Edge, Brave, Vivaldi. Also, there are lots of Electron applications that share some artifacts with them. Chrome is the point of convergence for all these application. On Magnet Summit it was suggested to explore and learn Chrome and it’s artifacts as well as OS common artifacts due to its popularity and reusing some of its components.
Electron
It’s a framework that is available for building applications, cross-platform. You’re creating a web-application that can be used as a desktop one (implementing both back- and frontend). Backend - node.js, and frontend - Chrome. So, a lot of artifacts can be shared with Chrome and buddies. It’s in wide use. For example, WhatsApp and Skype use it.
IndexedDB & LevelDB
Client-side web technology and supporteed by all of the mainstream browsers. Allows storage of structured user data on the client (JavaSctipt objects). Allows caching and storing some data for offline or tracking. The database structure is as follows:
Database:
- Object store (~table)
- Object (~row)
- Object (~row)
- Object (~row)
- Object store (~table)
- Object (~row)
- Object (~row)
- Object (~row)
Objects are addressable by their primary key or any other field that’s specified as index.
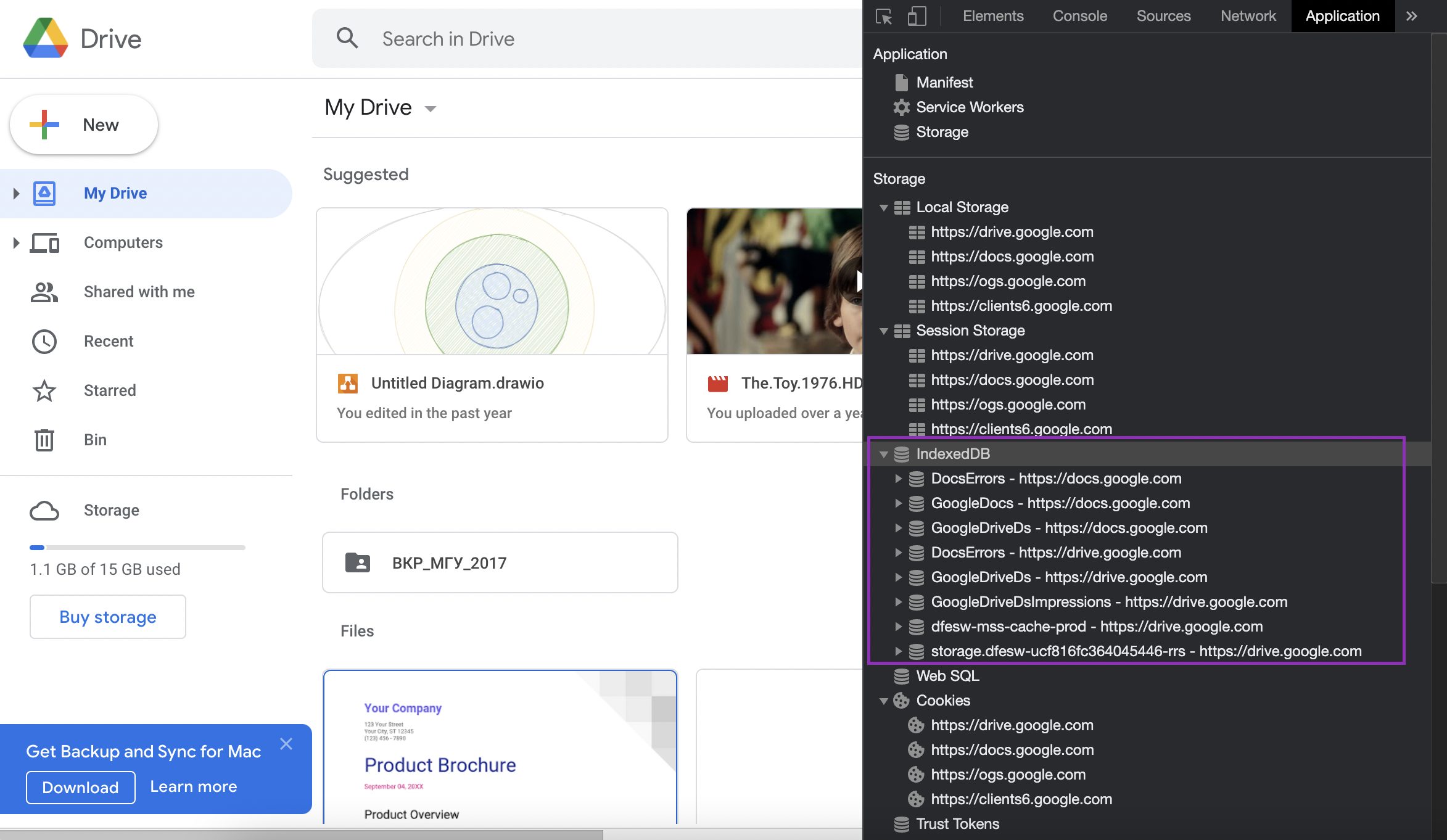
On the pictire above I’ve selected this IndexedDB (purple square). It’s more like Elastic of MongoDB (noSQL databases). It looks much more like a dictionary or hashtable to me. For example, Users table contains one single entry: ucf8XXXXXX45446, which has a set of properties like emailAddress, fasttrack, id, internal, locale (language of the GUI, I presume), optInReasons and optInTime. optInReasons, in turn, has it’s own property of type array with only one item with the value 0.
An example of working with such a database [4]:
dbOpenReq.onupgradeneeded = ev => {
document.body.append("db creating/upgrading");
let upgradedb = ev.target.result;
if(!upgradedb.objectStoreNames.contains("objStore1")){
let objectStore = upgradedb.createObjectStore('objStore1', {keyPath:'id', autoIncrement: true});
objectStore.createIndex("indexA", "indexA", {unique: false});
objectStore.createIndex("indexB", "indexB", {unique: false});
}
if(!upgradedb.objectStoreNames.contains("objStore2")){
let objectStore = upgradedb.createObjectStore('objStore2', {keyPath:'id', autoIncrement: true});
objectStore.createIndex("indexC", "indexC", {unique: false});
objectStore.createIndex("indexD", "indexD", {unique: false});
}
}
Storing the data is not complicated either:
var addData = () => {
let transcation = db.transcation(["objStore1", "objStore2"], "readwrite");
let objectStore1 = transcation.objectStore("objStore1");
objectStore1.add({"indexA": "a.1", "indexB": "Some data for indexB"});
objectStore1.add({"indexA": "a.2", "indexB": "Some more data for indexB"});
let objectStore2 = transcation.objectStore("objStore2");
objectStore1.add({"indexC": "c.1", "indexD": "Some data for indexD"});
objectStore1.add({"indexC": "c.2", "indexD": "Some more data for indexD"});
}
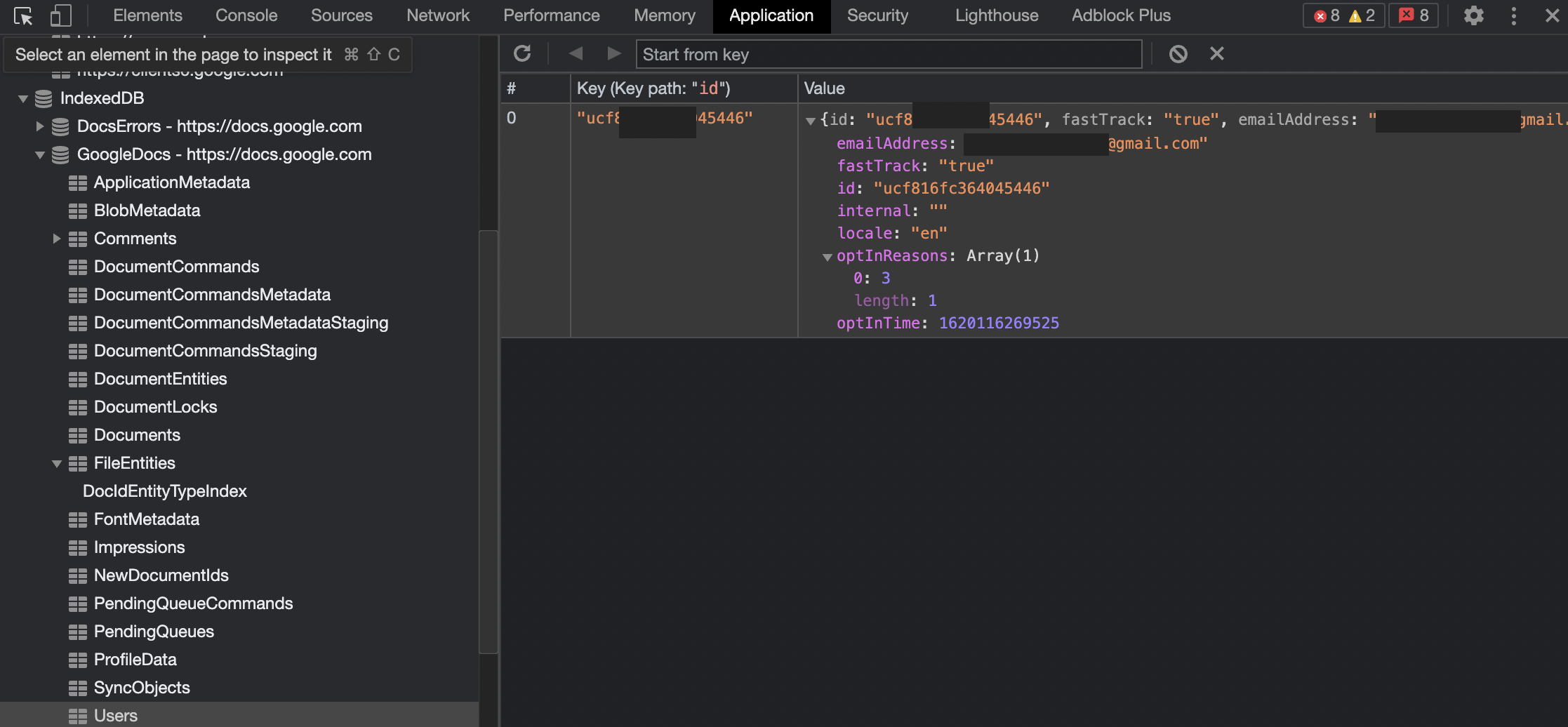
When you download a file from GoogleDocs, it’s stored in this IndexedDB -> Documents.
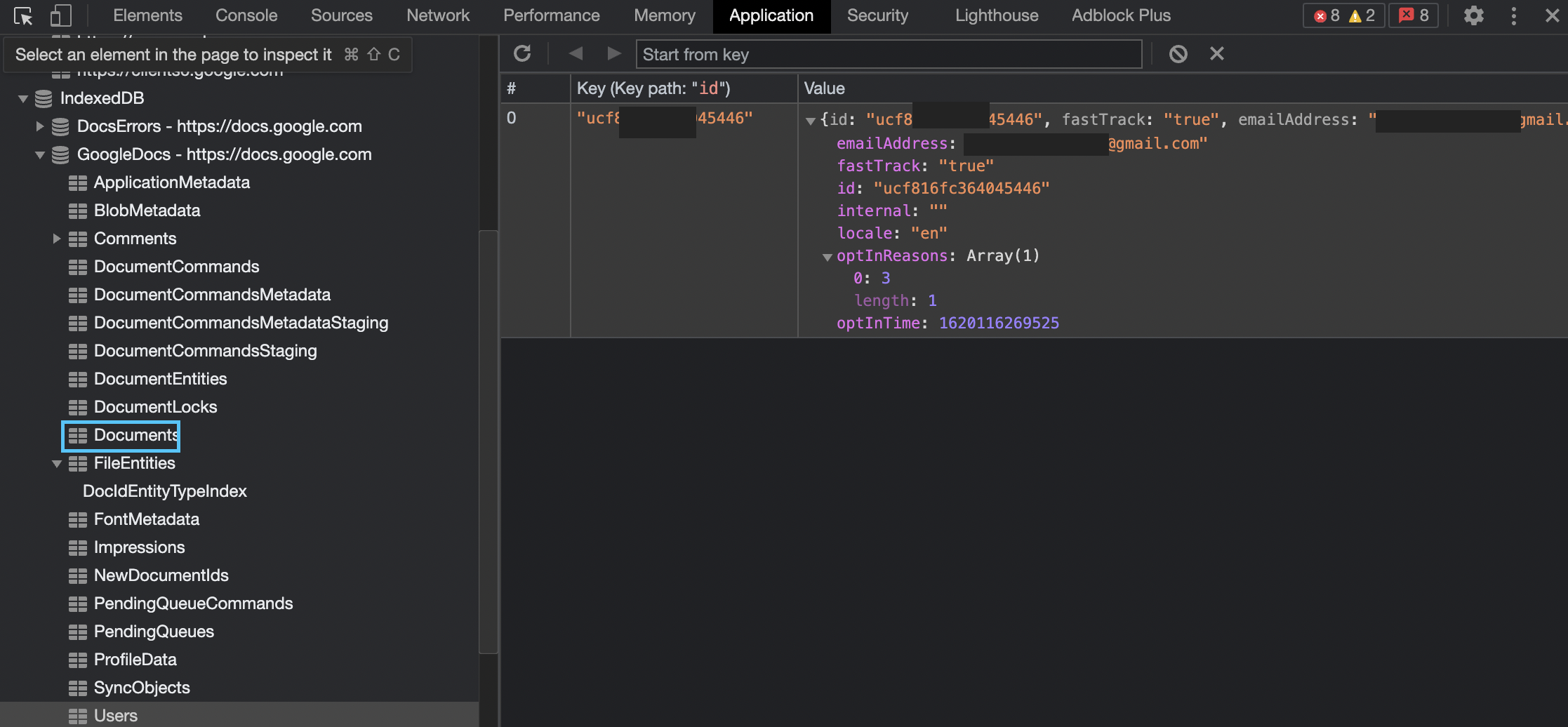
On Windows machine it’s stored here: $USER\AppData\Local\Google\Chrome\User Data\Default\IndexedDB. Contains multiple folders, one for each domain. Usually have the extension leveldb. The LevelDB store for a particular domain will be found in the IndexedDB folder with a name in the form: [host with concurrent separators replaced an underscore]_[dbid].indexeddb.leveldb.
LevelDB is the actual storage mechanism of IndexedDB, IndexedDB is built on top of a LevelDB store. IndexedDB is just an API to use, while LevelDB is the artefact that’s creted when this API is used. It’s based on the ideas of BigTable. It’s a key-value store, both are arbitrary blobs, i.e. can store any data in key or value. Looks something like the below picture.
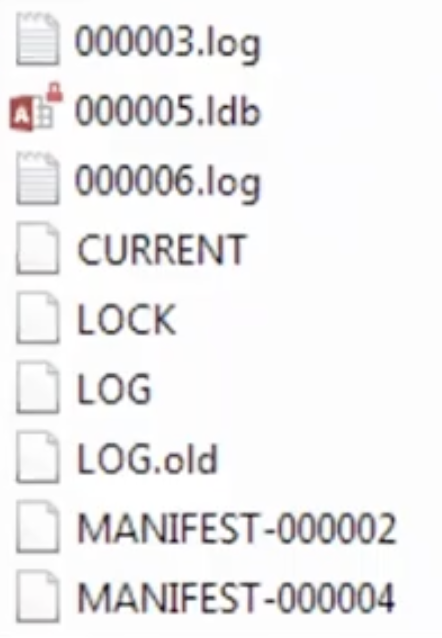
There are always CURRENT, LOCK, LOG and at least one MANIFEST. Only *.log and *.ldb files contain data. Other files above contain metadata. *.ldb doesn’t have to do anything with MS Access, although the OS might consider differently. As you can also notice, these files are assigned numbers which are sequential for all files in the folder, not for each file type.
The data in levelDB is stored in key-value pairs. Each time a pair is created (key being updated), it’s logged in one of those *.log files. When these logs are filled up, all these files (16 by default) are consolidated into a Level Zero LDB. When data is updates or deleted, these events are put into the logs. So, we are able to get those previous data values. When Level Zero LDB (4 files) are filled out, they are merged (sorted and de-duplicated) into one Level One file. All deleted data and updated will be removed.
LDB file format
.ldb files are made of blocks which are structured the same way but they have different purpose:
- Data.
- Meta. Might not be present.
- Meta Index. Location and sized of Meta blocks are listed here.
- Index. Location and sized of Data blocks are listed here.
- Footer. 48 bytes, always at the end. Starts with offsets and lengths of Index and Index Meta blocks. Contains the signature: 8 bytes at the end:
57 FB 80 8B 24 75 47 DB.
struct BlockHandle {
VarInt offset; // little-endian
VarInt size; // little-endian
}
BlockHandle structure is used in the footer for Index Blocks and in Index Block for Data and Meta Blocks Blocks.
Each block contains zero or more BlockEntry structs followed by a restart-array (for speeding-up data reading, but not mandatory). Blocks are always followed by a 5-byte long trailer: 1 byte defines comression (0 - none, 1 - snappy), 4 byte (CRC32 of data). This data is not included when calculating BlockHandle.size. Snappy compression algorithm is fast, but not utterly efficient, so, one might even see some recognizable strings. You can even get hits when performing keyword search.
Block entries contain the data for each key/value pair. Key is encoded using key sharing.
struct BlockEntry {
VarInt shared_key_length;
VarInt inline_key_length;
VarInt value_length;
inline_key;
value;
}
Key Sharing. Allows keys with common prefixes to be encoded efficiently. That means that a keyword search might miss some things. Example of key sharing:
theBestGirlEva (shared_key_length=0, inline_key_length=14, inline_key=theBestGirlEva);
theBestGirlNika (shared_key_length=11, inline_key_length=4,inline_key=Nika);
theBestBoyAlex (shared_key_length=7; inline_key_length=7; inline_key=BoyAlex);
In the last 8 bytes of the key there is metadata (56 bit sequence number of the operation that the levelDB has already performed, and key state either deleted or live). Added by the file format, not the programmer. So, you can always order the operations in levelDB. So, if one has different interactions with this key, in levelDB it’s going to have different sequence numbers.
Log File Structure
Consists of multiple 32k blocks of data and the data is never compressed. Has a 7 byte header:
| Size | Value |
|---|---|
| 4 byte | CRC32 |
| 2 byte | int16 data length |
| 1 byte | block type: 1 - full, i.e. only this block for this batch; 2 - First (first block in the batch), 3 - Middle, 4 - Last. |
Batch or Record format. Data written to levelDB can be batched. So, different blocks of log files can be batched together. Data will flow across those blocks, but the metadata at the start of each block will interrupt the record (batch) data at boundaries. Batch header = 12 bytes. The sequence number is the same as for the key sequence number.
struct Batch {
// header
int64 seq_num; // 8 bytes
int32 record_count; // 4 bytes
}
struct Record {
bool record_state; // 1 - deleted, 0 - live
VarInt32 key_length; //little-endian
key;
VarInt32 value_length; //little-endian
value;
}
No metadata is encoded in the key and no snappy!
Deleted Data
Logs and Level Zero LDB can potentially contain old versions of or deleted records, however, when moved at last to the Level One LDB, these records that contain deleted or updated records get erased. However Level One LDB might contain logically deleted data, if this data was marked for deletion in log or Level Zero LDB.
Data Types
Integeres are stored in little-endian format.
Floats are stored using the host’s endianess (usually little).
Text is encoded as ASCII, UTF-8 and UTF-16, but may also be a 8-bit value. Use big-endian notation.
VarInt. Is used to safe memory. For example, number 5 only occupies 1 byte, but 1032 will need two bytes to live. They are also little-endian values. But how to tell when the number ends? Easy, the most significant bit of every byte (byte being the smallest space occupied) tells the PC whether there are more bytes to come.
Read more about VarInt.
🛠 Tool for reading IndexedDB, still in development.
References
[1] IndexedDB on Chromium
[2] Hang on! That’s not SQLite! Chrome, Electron and LevelDB
[3] Protobuf and VarInt
Cookies
An example of creating a cookie:
document.cookie = "username=John Doe; expires=Thu, 18 Dec 2013 12:00:00 UTC";
There are several attacks on cookies (session hijaking, session fixation, reversing cookies when applicable).
WebStorage
An example of using localStorage:
localStorage.setItem('myCat', 'Tom');
const cat = localStorage.getItem('myCat');
localStorage.removeItem('myCat');
localStorage.clear();
An example of using sessionStorage:
// Save data to sessionStorage
sessionStorage.setItem('key', 'value');
// Get saved data from sessionStorage
let data = sessionStorage.getItem('key');
// Remove saved data from sessionStorage
sessionStorage.removeItem('key');
// Remove all saved data from sessionStorage
sessionStorage.clear();
Data in localStorage doesn’t expire, data in sessionStorage is cleared when the page session ends (is valid only for one particular tab). Openning the same web-application in another tab creates a new page session, which is different from the cookie mechanism. But! Duplicating the tab copies the tab’s sessionStorage into the new tab, i.e. and from that moment forward they might start being different.
As for the localStorage, private mode creates a new localStorage that’s cleared is cleared when the last “private” tab is closed.
Both localStorage and sessionStorage are read-only.
File System API
Psedo file system like environment for a web application.
WebSQL
Was never really officially documented, but now it’s deprecated (lot’s of vendor specific stuff), but was used some time ago, containing lots of interesting artifacts. SQLite.
Application Cache
Was used to cache web-application’s data locally. It’s deprecated but still available in most browsers.
Firefox
Localstore.rdf
No real value for the examiner here, since it contains customized data on the interface. Can be cleared in the GUI with “Reset toolbars and controls” option. [1]
addons.json
I think, the file name speaks for itself. It contains all the data for installed addons.
References
[1] About Localstore.rdf file
[2] Browser forensics
[3] Working with IndexedDB
[4] Magnet Summit 2021, Hang On! That’s Not SQLite! Chrome, Electron, and LevelDB
[5] About localStorage
[6] Hang on! That’s not SQLite! Chrome, Electron and LevelDB, article