
Developed in collaboration with IBM. POSIX compliant. Official docs for NTFS here.
❗️ Everything is a file! ❗️ All offsets are relative to the start of the data structures. ❗️ Apple macOS machines can read NTFS devices but do not support writing to them by default.
The entire logical volume is a data area (in contrast to FAT where there is a system area as well ❓).
In a Microsoft NT File System (NTFS), hot fixing of disk sectors prevents data from being stored in a bad sector or cluster.
The NTFS (New Technology File System) file system provides file-level security:
- NTFS permissions allow you to set specific access rights for individual users or groups on a file or folder. These permissions include read, write, execute, and delete access and more advanced permissions like modify, full control, and take ownership.
- You can also set permissions to allow or deny access to specific types of users or groups, such as administrators, authenticated users, or specific user accounts.
- NTFS uses ACLs to define more complex access control policies. ACLs allow you to define sets of permissions for multiple users or groups, and can be used to define more fine-grained access control policies. For example, you can create an ACL that allows members of a certain group to read and modify files in a particular folder, but denies access to other users.
- NTFS also provides other security features, such as file and folder encryption using BitLocker, and auditing to track access and modifications to files and folders. Overall, NTFS is a robust file system that provides a wide range of security features to help you protect your files and data.
Versions
V1.0
The first release of Windows NT 3.1. Windows XP and above. It allowed for data recovery, rollback (restore the system to the last stable state) and larger volumes. Windows 8 + faster data recovery and cross platform. Windows 10 + extended logging features.
⚠️ Windows Vista and above can obly be installed on a NTFS volume!
V1.2
Windows NT 3.51, included admin controls, compressed files and User Access Control (recycle bin for each user and own account).
\$Recycle.Bin\ ($R&$I)
\RECYCLER
Features
🪶 Journaling, aka transaction logging. Records change to the metadata of FS. 🪶 ACL 🪶 Compression 🪶 Change tracking 🪶 Disk usage quotas. So that one user won’t eat up the entire volume. 🪶 VSC 🪶 Hard and Soft links (required to be POSIX compliant). One file has several names - hard links. Several pointers to the same file - soft links. 🪶 Reparse points. Different file usage types. 🪶 ADS 🪶 Distributed link tracking. Some files have an object ID to track them across the system (when the file was renamed, how many times, where it was moved, etc). 🪶 Volume mount points 🪶 Sparse file support 🪶 Encryption 🪶 Single instance storage. Similar to soft links. How is it different?
💀 Anatomy
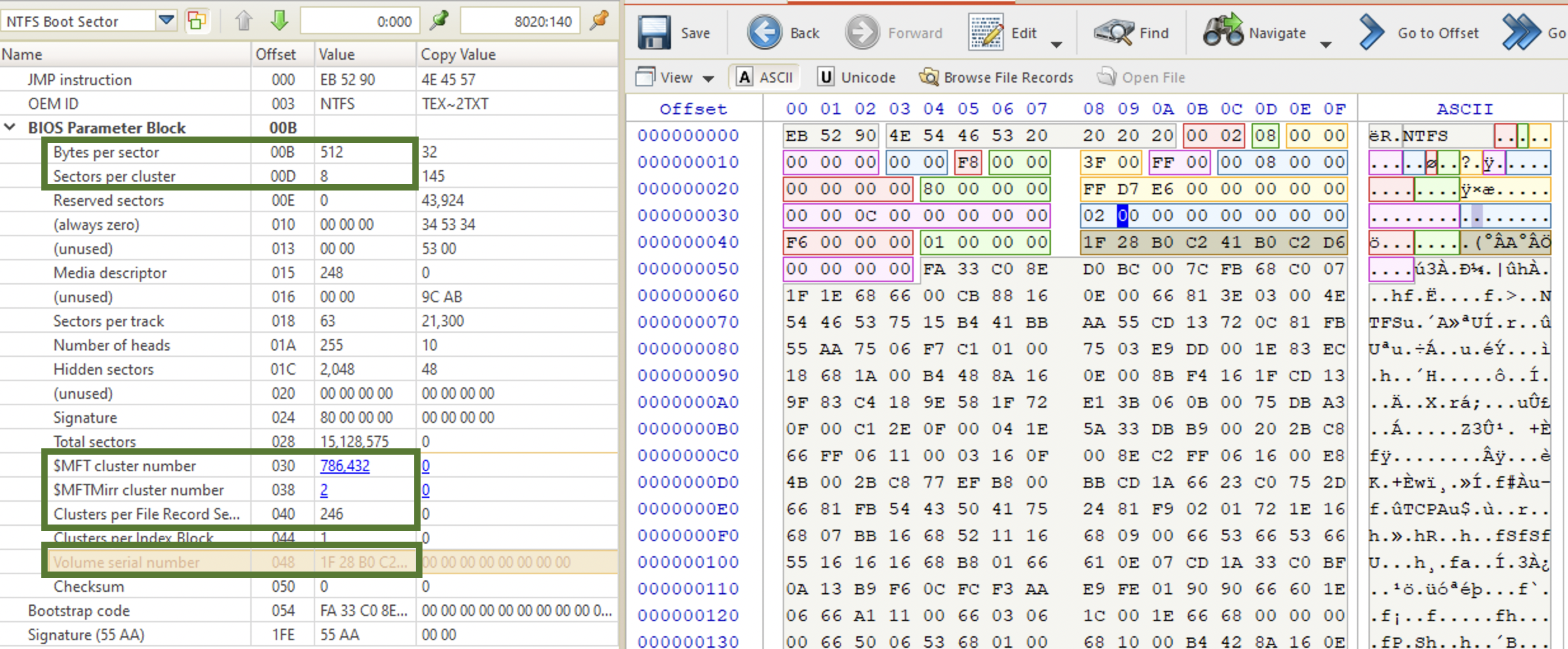
Volume Boot Record
In the $MFT is represented as $Boot. It’s located at the sector 0 of the volume (not physical disk!). Below is the VBR structure for NTFS. The most important entries for forensic purposes are highlighted.
MFT
The heart ♥️ of NTFS. Created once the disk/volume is formatted with NTFS. It’s an index of every single file on disk (at least 1 entry of a file), including NTFS metadata files (those that start with $). The first 26 records are for the system metadata files. Records 12-23 are reserved. Records 24-26 transaction log and error recovery. The first user-created file is usually at index 35.
Below is the full table of the files [6].
| Inode | Filename | OS | Description |
|---|---|---|---|
| 0 | $MFT | Master File Table - An index of every file. It describes the MFT itself. | |
| 1 | $MFTMirr | A backup copy of the first 4 records of the MFT that is required in case MFT gets damaged. | |
| 2 | $LogFile | Transactional logging file | |
| 3 | $Volume | Serial number, creation time, dirty flag | |
| 4 | $AttrDef | Attribute definitions. | |
| 5 | . (dot) | Root directory of the disk | |
| 6 | $Bitmap | Contains volume’s cluster map (in-use vs. free), used to identify open clusters. See more here | |
| 7 | $Boot | Boot record of the volume | |
| 8 | $BadClus | Lists bad clusters on the volume | |
| 9 | $Quota | NT | Quota information |
| 9 | $Secure | 2K | Security descriptors used by the volume |
| 10 | $UpCase | Table of uppercase characters used for collating | |
| 11 | $Extend | 2K | A directory: $ObjId, $Quota, $Reparse, $UsnJrnl |
| 12-15 | Unused | Marked as in use but empty | |
| 16-23 | Unused | Marked as unused | |
| Any (25) | $ObjId | 2K | Unique Ids given to every file |
| Any (24) | $Quota | 2K | Quota information |
| Any (26) | $Reparse | 2K | Reparse point information |
| Any | $UsnJrnl | 2K | Journalling of Encryption (usually at /$Extend directory, see above). Known as a Change Journal. |
These files cannot be opened from the user space, it’s maintained by NTFS driver. So, even if shown by Directory Snoop, you can’t open it on a live system. You can view the hex data though in DS-NTFS. Another option would be to make a disk image and carve the files. View some more information here [3].
\$Extend\$UsnJrnl. Journal change log for NTFS system. EVERYTHING! File and directory deletion, creation, and encryption.
$LogFile. It’s a transaction journal of $MFT. Very similar to $UsnJrnl, but lives less. Tracks file creation, modification, renaming and deletion. May not exist, but since Windows Vista $UsnJrnl is there by default.
📘 istat [options] image inode -z timezone # parses the information in the MFT entries.
A MFT record contains the following info and is usually 1024 bytes long:
- file allocation status
- file dates
- file name
- location
Every object gets an entry with attributes to describe it.
| 🗒️ FILES | 📂 DIRECTORIES |
|---|---|
0x10 $STANDARD_INFORMATION |
0x10 $STANDARD_INFORMATION |
0x30 $FILE_NAME (long) |
0x30 $FILE_NAME (long) |
0x30 $FILE_NAME (short, sometimes) |
0x30 $FILE_NAME (short, sometimes) |
0x80 $DATA |
0x90 $INDEX_ROOT |
0x80 $DATA (ADS, sometimes) |
0xA0 $INDEX_ALLOCATION (sometimes) |
Volume name also gets an entry (always #3 for the $VOLUME system file).
Records start at index 0 (for the MFT record itself) and are numbered sequentially. Each record is usually 1024 bytes. New records are created on a first-available basis, i.e. if a record was deleted (deallocated), it gets overwritten once a new one is created, and the deallocated one is the first free index in the table.
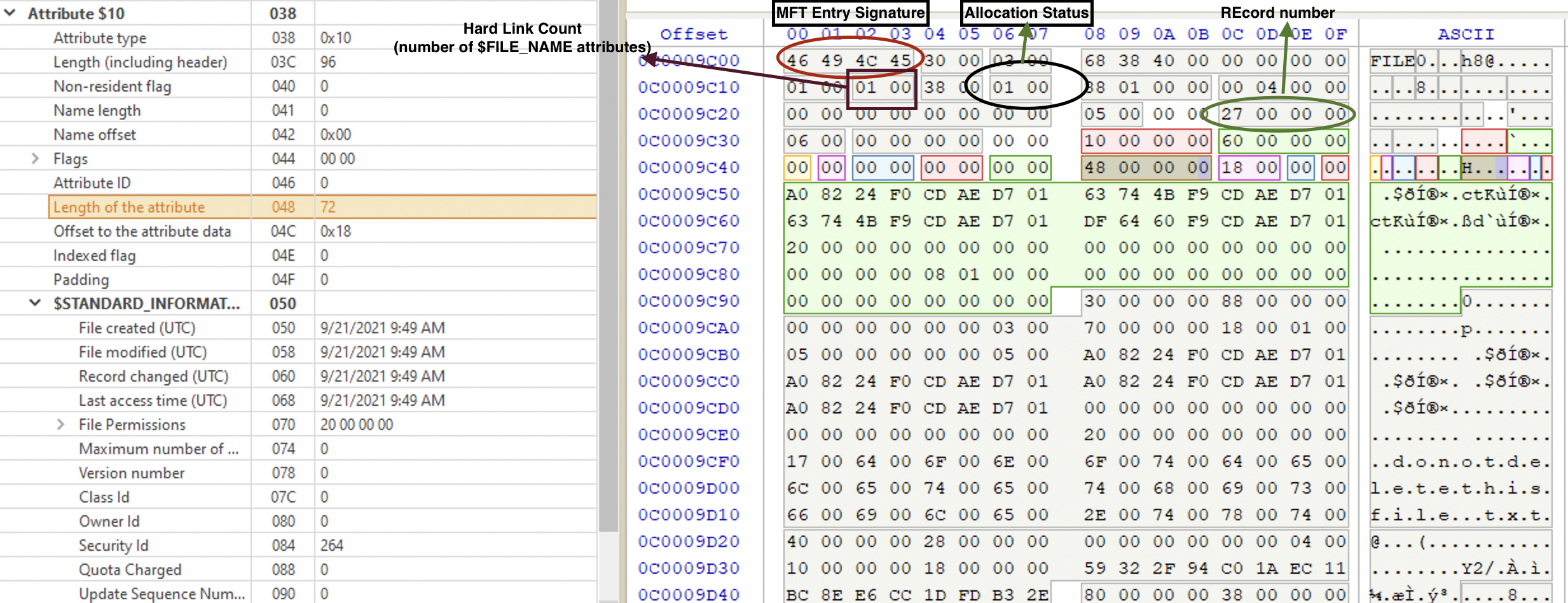
A file record begins with a header (ASCII FILE or BAAD if corrupted). It contains info about the file. It’s made up of attributes. Each of them contains specific information about the file record entry. Each record ends with a 0xFF FF FF FF. It has a sequence number at offset 0x10 2 bytes long, incremented each time the file is deleted (not allocated ❗️). At offset 0x16 there is an allocation status flags: 0x00 for deleted file, 0x01 for allocated one, 0x02 for deleted dir, 0x03 for allocated dir.
# if you have an MFT record number, you can pass to istat
📘 istat imagefile MFT_record_number
# output:
> allocation status
> MFT entry number
> $LogFile sequence number
> $Standard_Information attribute (flags, security info, $UsnJrnl number, MACB timestamps)
At the offset 0x10 you can see aa sequence number that gets incremented when the file is deleted. When the MFT entry was created for the first time, the value is set to 1. When the file is deleted, the value is incremented by 1. Then, when this entry is reused, the sequence number remains the same and only gets incremented when the file is deleted, and the entry gets unallocated again.
Hard Link count at offset 0x12 specified how many $FILE_NAME attributes this file has. This includes both long and short names as well as real hard links.
At offset 0x16 we can see a flag which can have either of the following values:
🇬🇧 0x00 0000 Not in use
🇬🇧 0x01 0001 file in use
🇬🇧 0x02 0010 dir deleted
🇬🇧 0x03 0011 dir in use
When the file is deleted, the flag is set to 0x0, but the rest of the MFT entry remains intact until it’s reused by another file.
Data at 0x18 and 0x1C show the real and allocated (including slack) space for this FILE record. At 0x20 we can see the File Reference to Base Record which can be something other than 0 sometimes when there are too many attributes for the given file to fit in 1024 bytes.
At the offset 0x28 we will see the Next available attribute ID. Each will have a unique ID that starts at 0.
At the offset 0x2C we have the inode (MFT entry ID) number. This data was added to the newer NTFS versions, changing the length of the data. So, the pointer to the fix-up array at the beginning (offset 0x4) used to be 0x2A (* in ASCII) on older versions is now 0x30 (0 in ASCII). Keep that in mind when carving for FILE records.
Finally, we have fix-up information at the 0x30 offset. Here is how the fix-up works:
- Read the records two sectors from the MFT.
- Read the two byte offset of the Update Sequence Array located right after the four byte record magic value
- Compare the first number in the array to the number at offset 510 in sector 1
- If the values do not match indicate and error. This is when ‘chkdsk’ could be run
- Repeat steps 3 and 4 for sector 2
- Take the next value in the Update Sequence Array and write it at offset 510 in sector 1
- Repeat step 6 for sector 2
Following the header, there are four attributes (each consists of a header and contents):
Directories. A directory is almost a file, but instead of data, it contains references to other files. Sometimes, even unallocated $INDEX_ALLOCATION has a list of files’ $FILE_NAME values. $INDEX_ROOT is always present, and $INDEX_ALLOCATION is only needed when there are more entries. The latter looks pretty much like $DATA for files. $INDEX_ROOT + $INDEX_ALLOCATIONS (optional) = $I30.
$INDEX_ALLOCATION/$INDEX_ROOT header starts with an INDX magic number (0x49 0x4E 0x44 0x58). At the offset 0x20 allocated size of entries is specified, and the offset 0x1C holds the real size of the entries. Given these two values, we can calculate the slack space which might contain some residual data from previously deleted/deallocated entries. The header takes 0x40 bytes.
At the offset 0x40 the $I30 index entry starts. The first 8 bytes are MFT number. It points to the MFT entry that holds all the metadata about the file. Some info like ⏰ timestamps ($STANDARD_INFORMATION) and filenames are copies from the MFT entry to improve performance. Each folder and file has its entry here. Each entry has a 16-byte long header. At the offset 0x60 we have four (bmca) ⏰ timestamps 8-byte in size. At the offset 0x90 we have name length (2 bytes) and type followed by the file name itself.
This index is a B-tree that needs to be rebalanced from time to time, leaving some interesting data in the slack space during this process.
User 🛠️ indx2csv and 🛠️ Velociraptor can be both used to parse this artefact. Also, 🛠️ INDXparse.py parses individual $I30 only. Also, 🛠️ icat can be used to extract the index from the image.
📘 icat image MFT_num-160-attr_id > $I30 # extract the index from the disk image
📘 indx2csv /IndxFile:G:\cases\$I30 /OutputPath:G:\cases
📘 Velociraptor artifacts collect Windows.NTFS.I30 --args DerectoryGlobs="F:\\Windows\\Temp\\Permon" --format=csv
Standard attribute
Starts with 0x10. Standard attribute (file permissions, ⏰ timestamps, security and admin info). Below is the attribute highlighted. Note, that there are very useful timestamps at 0x18: file created/modified, record changed and last access time. ❗️ All UTC.
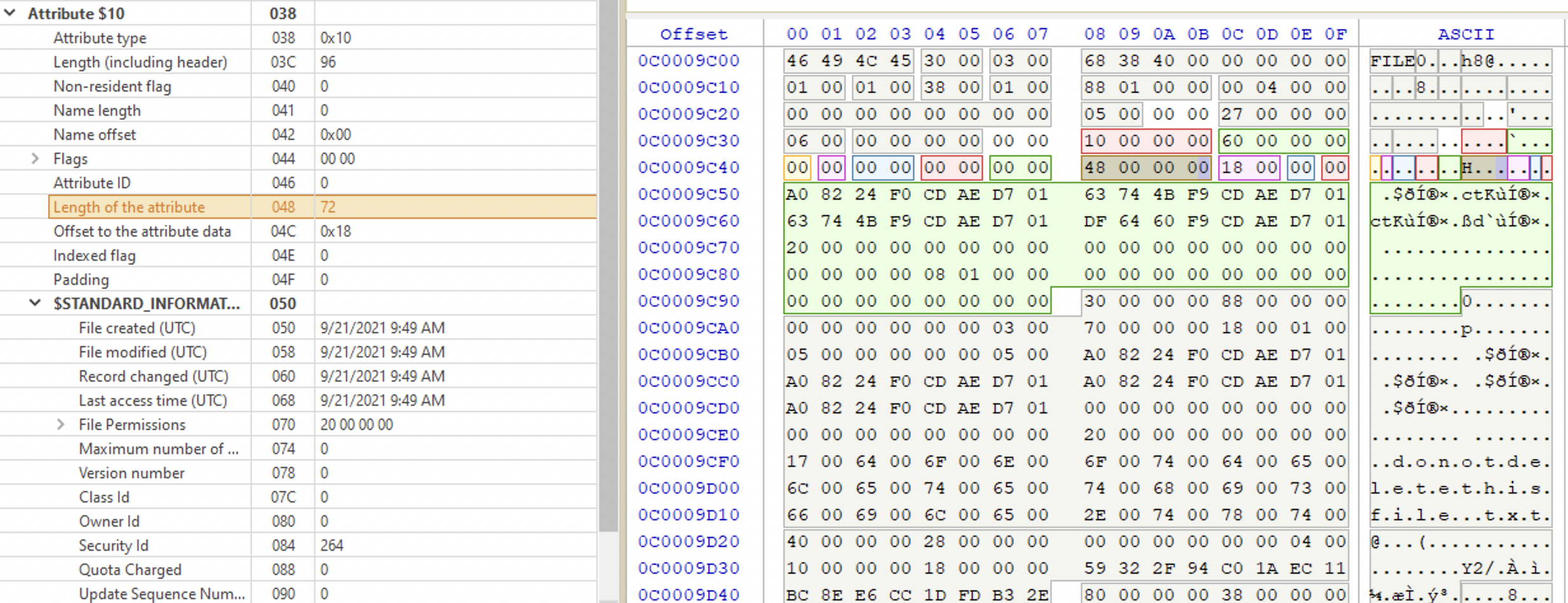
At offset 0x38 we have flags, showing the file attributes. Possible values are:
🇬🇧 10 00 00 00 Directory
🇬🇧 20 00 00 00 Archive
🇬🇧 40 00 00 00 Device
🇬🇧 30 00 00 00 Normal
🇬🇧 01 00 00 00 Read Only
🇬🇧 02 00 00 00 Hidden
🇬🇧 04 00 00 00 System
🇬🇧 00 10 00 00 Offline
🇬🇧 00 20 00 00 Not Indexed
🇬🇧 00 40 00 00 Encrypted
🇬🇧 00 0100 00 Temporary
🇬🇧 00 02 00 00 Sparse File
🇬🇧 00 04 00 00 Reparse Point
🇬🇧 00 08 00 00 Compressed
Note that each flag has only one specific bit at a fixed offset set. When there are multiple flags for one file, their values are combined. For example, to calculate the final flag value for a file which is an archive (🇬🇧 20 00 00 00) and is both a hidden (🇬🇧 02 00 00 00) and a system file (🇬🇧 04 00 00 00) we would have 20 as the first byte and 0x02 + 0x04 as the second, resulting in the flag value being set to 0x26. If this file were also
encrypted, we would have 0x2640.
File name
Starts with 0x30. It also has ⏰ timestamps, but for the filename. The first 6 bytes are for the parent directory’s MFT record (it’s not a cluster number like in FAT). The timestamps below are for the filename changes, not the changes for the file itself. For the file timestamps, see the attribute 0x10 (above). If the file is resident, its contents will be contained in the MFT. If the file is too big, there will be a data run instead (❓).
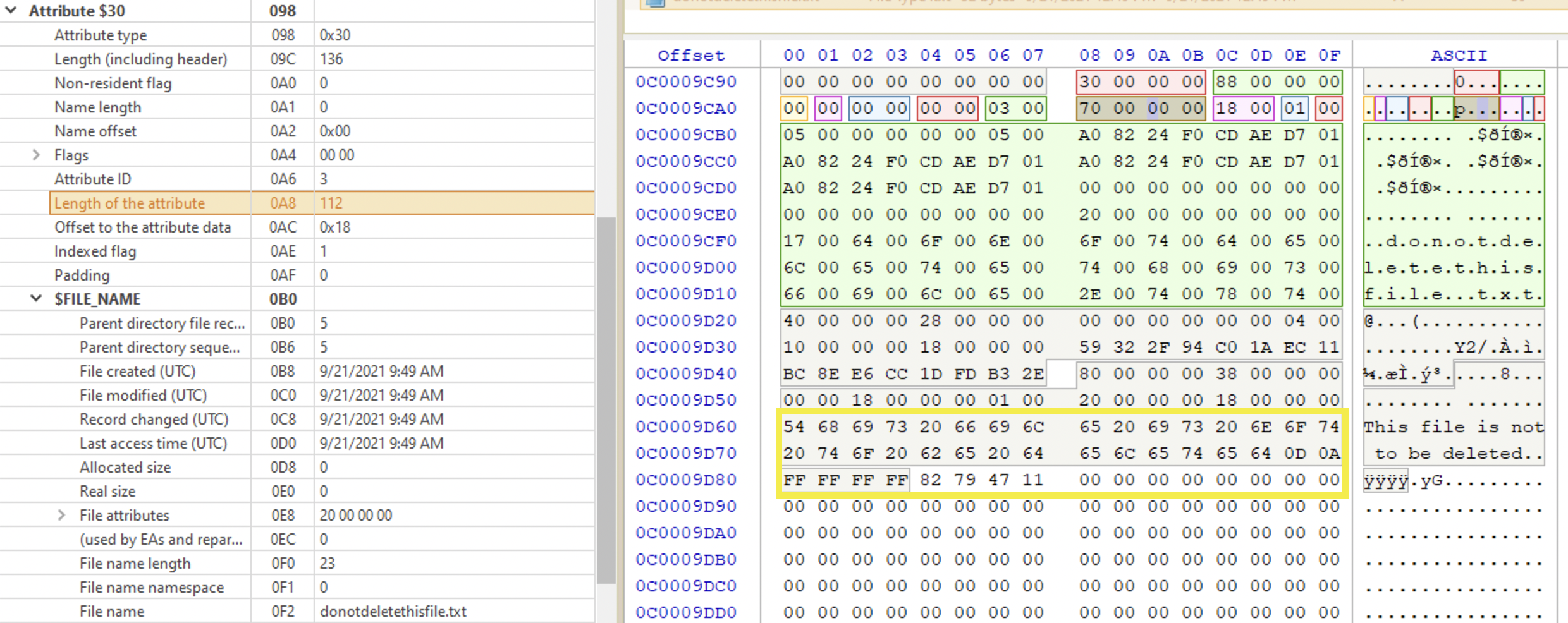
Contains 🐾 objects name, 🐾 parent folder and ⏰ filename timestamps which are not natively shown by Windows. It also includes 🐾 file properties like if it’s an archive or a hidden file.
At the offset 0x18 we have the parent directory reference specified. The first 6 bytes are the MFT entry number of the directory, and the remaining 2 represent the sequence number for this MFT record.
Another set of ⏰ timestamps begins at the offset 0x20.
The flags at the offset 0x50 are the same as in $STANDARD_INFORMATION.
At the offset 0x58 we have the number of Unicode characters that the filename consists of. Since Unicode characters are two bytes long, we need to double this number to get the exact number of bytes to read. Since this value is only one byte long, the max value it can have is 0xFF which is 255 in decimal. That’s why you can’t have a filename longer than 255 characters. And then, at the offset 0x59 we have a namespace type which can be either of the following: 0x00 for POSIX (different case - different name), 0x01 for Win32 (case-sensitive long name), 0x02 for DOS (DOS-compatible short name) and 0x03 for Win32/DOS (the name is short enough to only have one $FILE_NAME, DOS-compatible). If the file name is long enough, the second $FILE_NAME attribute is created which preserves the case.
Data attribute
⚠️ Yes, data is considered an attribute in NTFS. Starts with 0x80. Contains data itself or the pointer to its location (depending on the file size). If the file is small enough, its contents will be here (below, green area). In this case the file is called resident file. Whether it’s a resident file or not, you can determine by the non-resident byte (marked with a red rectangle in the picture below). In the picture below it’s 0x00, which means the file is resident and its contents is in the MFT record (right below). Marked with a green rectangle it’s the offset to the data, for resident files it’s always 0x0018 (little-endian), since the start of the data section is in the attribute itself at the fixed place.
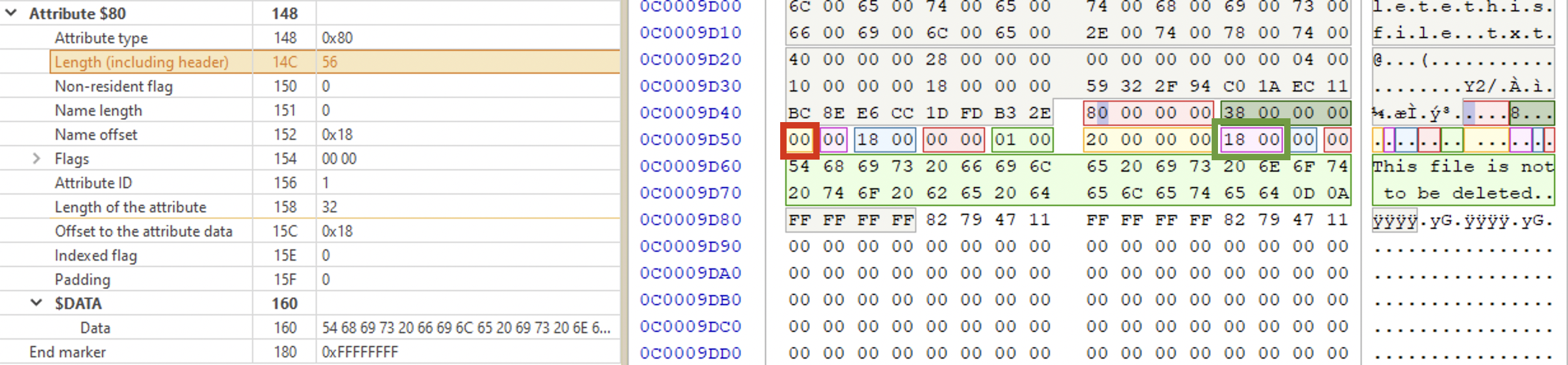
In the picture below there is an example of a record for a bigger file. Its non-resident flag is set to 0x01 (marked with a purple rectangle), meaning the contents is somewhere else on the disk. In order to find the file contents location, we need to perform the following steps:
- get the offset to data runs, which contain directions to the location of the content (pointer). In the picture below it’s
0x0040(little-endian). This offset is relative to the attribute start. So, we count0x40from the attribute start and get to the location marked with a dark-red rectangle:21 10 89 09 00 00 00 00(run list). - read the run list.
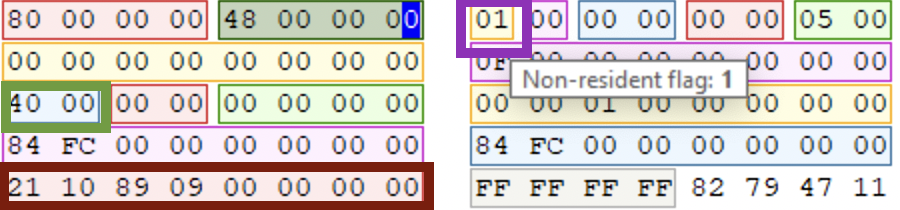
Now, what’s a run list?

In the picture below this structure is highlighted on the left and expalined on the right. The first byte is the run header, it tells the number of bytes, occupied by the run list. The second byte tells the length in clusters. The next two bytes are for the starting cluster number (signed 16-bit value). End the remaining 4 bytes of zeroes - end of run.
⚠️ To interpret the run header, split the byte into two nibbles and add them together:
2+1=3, meaning, in the example above the run list length is 3 bytes. The first nibble (2in this example) tells that the size of the first cluster field is 2 bytes. The second nibble tells that the size of the cluster count field of 1 byte (1). Together combined it’s 3. meaning that both cluster count and first cluster fields are 3 bytes long.
If the file is fragmented, there will be more than 1 data run. If there are more than 1 data run, then each next first cluster field is relative to the previous one. For example, if the first cluster for the first fragment in the first data run was 0x42A9 (17065 in decimal), and the next first cluster for the next fragment in the next data run is 0xBFBF (-16449 decimal) then in order to get the first cluster for the second fragment, we would substitute 16449 from 17065 which would give us 616 decimal value, which would be the first cluster of the second fragment [5]. So, each value is relevant to the last piece. To get the first cluster of the next fragment you’d add it’s value to 616 and so on and so forth. Active@Disk Editor does that automatically.
ADS
On Windows machines (NTFS file system), it’s possible to “append” a file to another file in such a way that this file is not visible with standard tools. This notion is called an alternate data stream. A few things to note:
- The host file’s hash is not changed, because, technically, it is not a part of this file. To check use 🛠️
fciv - The host file’s size is not changed, again, because technically, it is not a part of this file.
- These files are not visible for the file system and therefore, such tools as cmd, PowerShell, Explorer or others won’t see them if don’t know the magic 🪄 word. Even if you run
📘 type filewithlitter.txtyou won’t see the stream file’s contents, only the main one. - When you copy files from and to a FAT partition - all residual files will be deleted.
Now, if there are several streams for one MFT entry, the first one doesn’t have a name specified and inherits it from the $FILE_NAME attribute. All other $DATA streams need to have a name and can all be either resident or not.
To extract the data from the $DATA stream:
📘 icat [options] imagefile inode > data.data # -r recovers deleted files, -s displays slack space.
# To extract ADS
# You can also pipe this output through xxd to review the data in hex
📘 icat [options] imagefile inode-attributetype-id > data.data # where attribute type is also a number
Zone.Identifier. One of the ADS that can be of use and is present for some files is called Zone.Identifier. When a file is downloaded from the Internet using IE or Edge (or some other apps), an ADS is added to the file on an NTFS file system. This Zone.Identifier stream contains metadata about where the file came from. Here are possible values for this metadata:
ZoneId=0 for the Local Machine zone
ZoneId=1 for the Local Intranet zone
ZoneId=2 for the Trusted Sites zone
ZoneId=3 for the Internet zone. This is of particular interest for the investigation. What files are ok to be downloaded from the Internet? Would you expect svchost.exe to be downloaded?
ZoneId=4 for the Restricted Sites zone
Custom. To ensure compatibility between NTFS and HFS. Allows hiding files.
📘 C:\type C:\mal.exe > C:\readme.txt:naughty.exe
📘 start readme.txt:naughty.exe
📘 C:\mklink innocent.exe readme.txt:naughty.exe
📘 dir /r # displays all streams
🛠️ lns and 🛠️ sfind will hunt down such files.
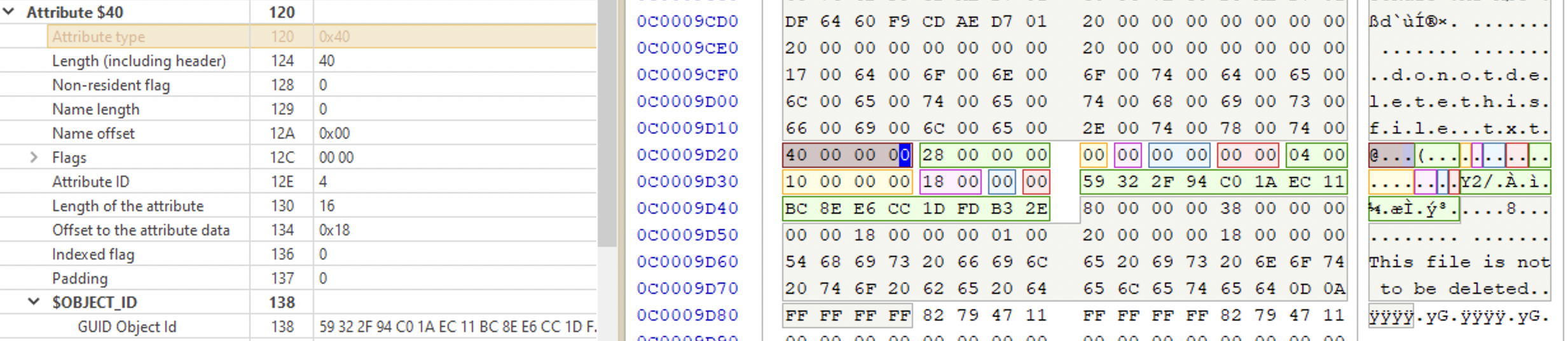
Object ID attribute
Starts with 0x40. This attribute contains a GUID of a file.
Bitmap attribute
Starts with 0xE0?0xB0?. ⁉️
Each MFT entry needs to be allocated and can get unallocated. When the MFT is allocated, it points to a cluster the file contents reside (if non-resident, of course). However, if the entry was unallocated (the file was deleted), the metadata may or may not be filled out. Keep in mind that in that case, the clusters that were used by that data could be reused.
✍️ MFT records often come in bunches if created in close proximity to each other. This doesn’t happen all the time, but it can sometimes be used to see if the timestomping took place. For example, the file claims to be created a month ago, but it has the same ids as files that were created yesterday. When executables were saved to disk and then run shortly afterwards, expect to see MFT records corresponding to exe itself and its respective prefetch files to have similar ID values.
$LogFile And $UsnJrnl
Both are parts of the journaling (transactional logging) capability of the NTFS. $LogFile tracks file system changes, $UsnJrnl however, is different.
$LogFile records data that needs to be inserted into $MFT, $I30 Indexes, $UsnJrnl etc. One simple file creation event can spawn numerous logs in $LogFile. It’s default size is 64MB (that’s usually around 4 hours worth of events on an active system).
📘 chkdsk volume /L # get the current size
📘 chkdsk volume /L:size # change the size
❗️ So, if the file is resident, it gets recorded. If not - the file content will not be recorded. Only the data changed or inserted will be logged in the payload. When the file is not resident, data run clusters can be recorded, which can help retrieve deleted data if it is not overwritten.
🐾 operation 🐾 f_name 🐾 current attribute 🐾 ⏰ timestamps (when changed) 🐾 payload
❗️
$LogFiledoes not include timestamps for each event! Log Sequence Number is used instead. Timestamps in the$LogFileare only recorded when changed in the$MFT. However,$LogFilelogs changed made to$UsnJrnlwhich contains the timestamps of the change.
📘 LogFileParser /ReconstructDataruns # to retrieve clusters for deleted files.
Two tools can be used 🛠️ LogFileParser (freeware) and 🛠️ TZWork’s mala (💰 commercial).
See here and here for more info about this artefact. When reviewing the $LogFile you can filter by parent directory to only include relevant events (for example, System32 folder or by extension). You can also sort or filter by Parent Entry Number if you know the folder used by the attacker. Use 🛠️ LogFileParser to process the file and output LogFile.csv (summary file), where some entries point to corresponding supplementary files for more info (for example, LogFile_INDX_I30.csv). LogFileNames.csv will list all file names present in the $LogFile.
$UsnJrnl provides a high-level summary of the changes made to files and directories. The logs usually contain a few days or several weeks’ worth of data. Each event type has a corresponding code. Backup and scanning software might use this file to check the latest changes to be updated with. There will be fewer events in this file, unlike $LogFile. It can, for example, track FileCreate events.
❓Does 🛠️ ProcessMonitor use this file to find
FileCreateevents?
🐾 f_name 🐾 MFT number 🐾 parent dir’s MFT number 🐾 ⏰ timestamp of the change 🐾 reason code 🐾 file size 🐾 attributes (hidden, archived etc)
The data recorded is stored in the $J ADS of $UsnJrnl. $J is a very large sparse data stream (much of it are zeroes). It has a lot of unallocated data. Another ADS $Max (32 bytes) contains metadata about the $UsnJrnl itself. For USN reason codes, see this Microsoft documentation.
❗️Records are not numbered and tracked based on their offset within this file. Each file and directory in
$MFThad an Update Sequence Number pointing to the specific offset within$UsnJrnl:$Jfile.
📘 fsutil usn queryJournal # check the size of UsnJrnl
📘 mftecmd.exe -f F:\C\$Extent\$J --csv pathtooutput --csvf results.csv # if this is a KAPE triage image was mounted as F drive, point to the $J file directly
📘 mftecmd.exe -f F:\C\$Extent\$UsrJrnl\$J --csv pathtooutput --csvf results.csv # IF the full disk image was mounted as F:, point it to the $J file.
Another tool to parse $UsnJrnl is TZWork’s 🛠️ jp.
| action | $LogFile | $UsnJrnl |
|---|---|---|
| F/D created | AddIndexEntryAllocation, InitializeFileRecordSegment |
FileCreate |
| F/D deleted | DeletelndexEntryAllocation, DeallocateFileRecordSegment |
FileCreate |
| F/D renamed or moved | DeletelndexEntryAllocation, AddlndexEntryAllocation |
RenameOldName and RenameNewName |
| ADS created | CreateAttribute with a name ending in : ADS |
StreamChange and NamedDataExtend |
| File meta modified | * Op codes for $LogFile often are not sufficient to determine file modification | DataOverwrite |
File Creation and Deletion
Creating Files
Steps to create a file:
- A file record (
FILE) is created in$MFT - The bitmap for the $MFT is changed to indicate the record is allocated❓
- The record header allocation flag shows it as an allocated file or directory
- Attributes are written to the $MFT file record
- If the data is non-resident, the $BitMap file is updated to represent the clusters allocated to store the data
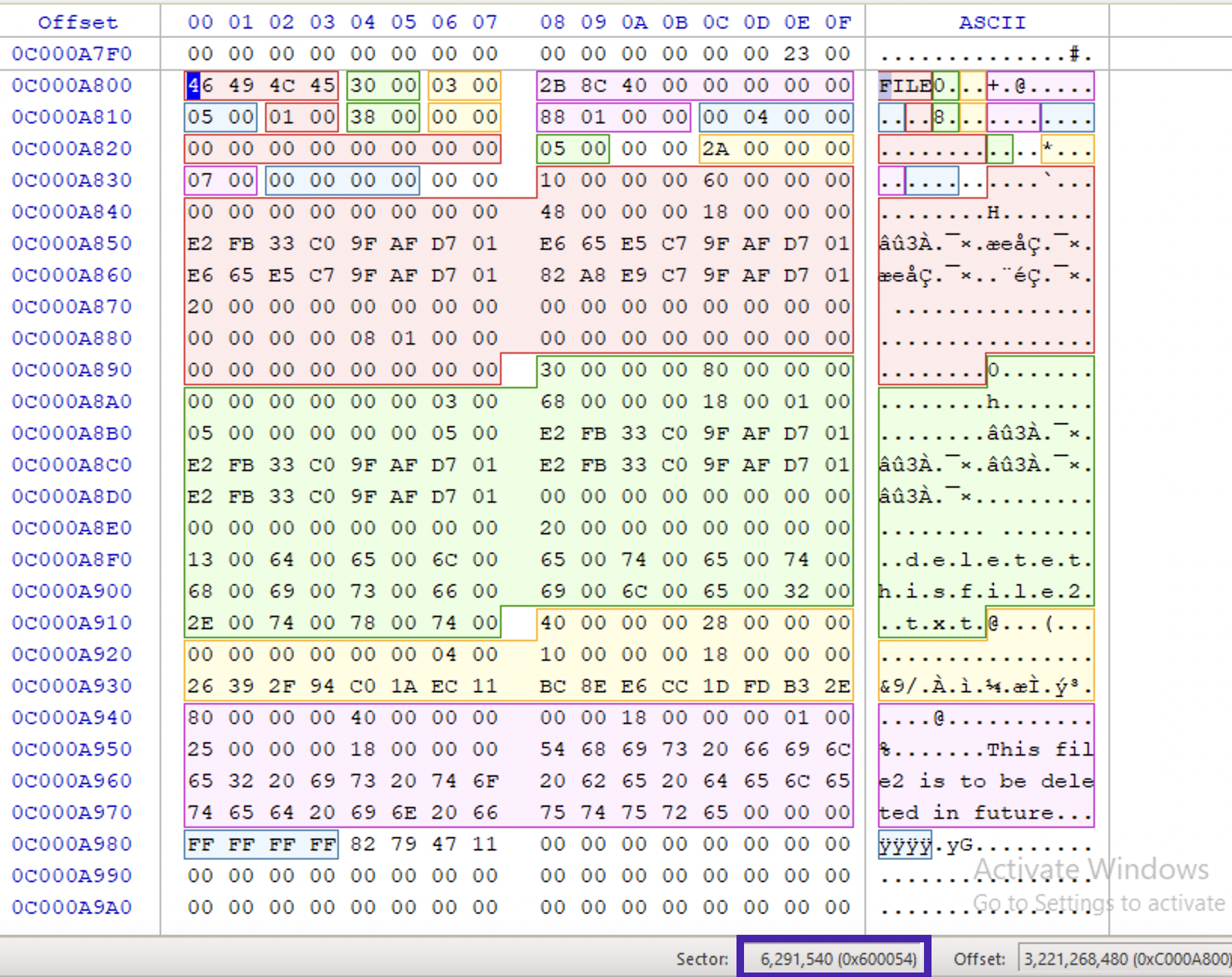
Go to “Browse File Records” on the top pane, choose the newly created file and see its attributes. The most important are sequence number and flags. I’ve noticed that when I create and delete files several times, the MFT file record remains the same, the sequence number just gets incremented. That’s because NTFS uses the first free record when the file is created. If you know at which sector a resident file was located before deletion, you can view its contents before it gets overwritten. The sector number is shown on the very rightmost bottom pane in Active@Disk Editor:
Deleting Files
Steps taken:
- In the
$MFTthe record header sequence number (see above) is incremented (allocation flag) -
$MFTrecord is marked as available but not overwritten. -
$Bitmapfile marks clusters as free, but the data at those clusters is not yet touched. If the data is non-resident, the $BitMap file is updated to indicate the clusters are unallocated. - The parent directory marks this entry as available, possibly triggering rebalancing (may or may not overwrite the index entry).
-
$LogFileupdated. -
$Secure,$ObjIDand$Quotaare updated. -
$UsnJrnlupdated.
❗️
$FILE_NAMEis not changed until the$MFTentry is reused.❗️
$I30maybe preserved.
⏰ Timestamps
📆 Jan 1, 1601. UTC?
Modified, Accessed, Created, MFT Modified.
Sources: $Standart_Information, $Filename (if the file name is long enough, there will be two $FILE_NAME attributes, each with its own MACB timestamps set, $I30_Index.
Modified
Created
Accessed
Sometimes this option might be turned off. To check, check the NTFSLastAccessUpdate key at HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem in Windows Registry.
Can be changed with fsutils:
fsutil behavior set disablelastaccess [0|1|2|3]
# restart the PC
| Value | Description |
|---|---|
| 0 | User Managed, Last Access Time Updates Enabled |
| ❗️1 | ❗️User Managed, Last Access Time Updates Disabled |
| 2 (default) | System Managed, Last Access Time Updates Enabled |
| 3 | System Managed, Last Access Time Updates Disabled |
Use the poster to help. It will show how different file system timestamps change depending on the activity performed with the file. There are 4 timestamps used on NTFS: M (modification 🍉), A (access 🍏), C (Metadata change 🍒) and B (file created/born 🍌).
- File Renamed:
$Standard_Information🍒,$Filename- none - Local file move:
$Standard_Information🍒,$Filename- 🍉🍒 - Volume file move:
$Standard_Information🍏🍒,$Filename- 🍉🍏🍌 🍒 - File copy:
$Standard_Information🍏🍌🍒 ,$Filename- 🍉🍏🍌 🍒 - File Access:
$Standard_Information🍏 (old Win) ,$Filename- none - File Modify:
$Standard_Information🍉 🍏 🍒 ,$Filename- 🍉 🍏 🍒 - File Creation:
$Standard_Information🍉🍏🍌 🍒,$Filename- 🍉🍏🍌 🍒 - File Deletion:
$Standard_Informationnone,$Filename- none
✍️ If you see that a file was created 🍌 AFTER it was modified 🍉, it is indicative of a file copy, even when the file was copied from another system. It can sometimes highlight the lateral movement event.
❗️Each file and directory will have
$STANDARD_INFORMATION(4 timestamps) and at least one$FILE_NAME(another 4 timestamps). If the filename is long enough, the second $FILE_NAME attribute will have the additional 4 timestamps.
References
[1] Windows OS file system for 27 years
[2] Demystifying Mac Investigations: Mac vs. Windows Artifacts Comparison, Magnet Webinar
NTFS file system, Suhanov’s blog: [1] Playing with case-insensitive file names, [2] $STANDARD_INFORMATION vs. $FILE_NAME, [3] Exporting registry hives from a live system, [4] Trim and unallocated space, [5] OneDrive and NTFS last access timestamps, [6] Deceptive NTFS short file names, [7] You write to a logical drive when you read from it, [8] NTFS: large clusters, [9] NTFS: unallocated data marked as allocated, [10] How the $LogFile works?, [11] NTFS today, [12] Hibernation and NTFS, [13] The (in)consistency of last access timestamps, [14] The “Last Access” updates are almost back.
[3] How to acquire “locked” files from a running Windows system, By Pär Österberg Medina
[4] Opening $MFT file causes Access denied even if run as administrator, StackOverflow, answered by Eric Brown
[5] Digital Forensics Specialization, Windows OS Forensics course, InfoSec Institute, Coursera
[6] NTFS Documentation
[7] About FAT32